
Decoupling the Probabilistic Black Box:
Technical Architecture and Governance Frameworks for Secure Enterprise AI Integration

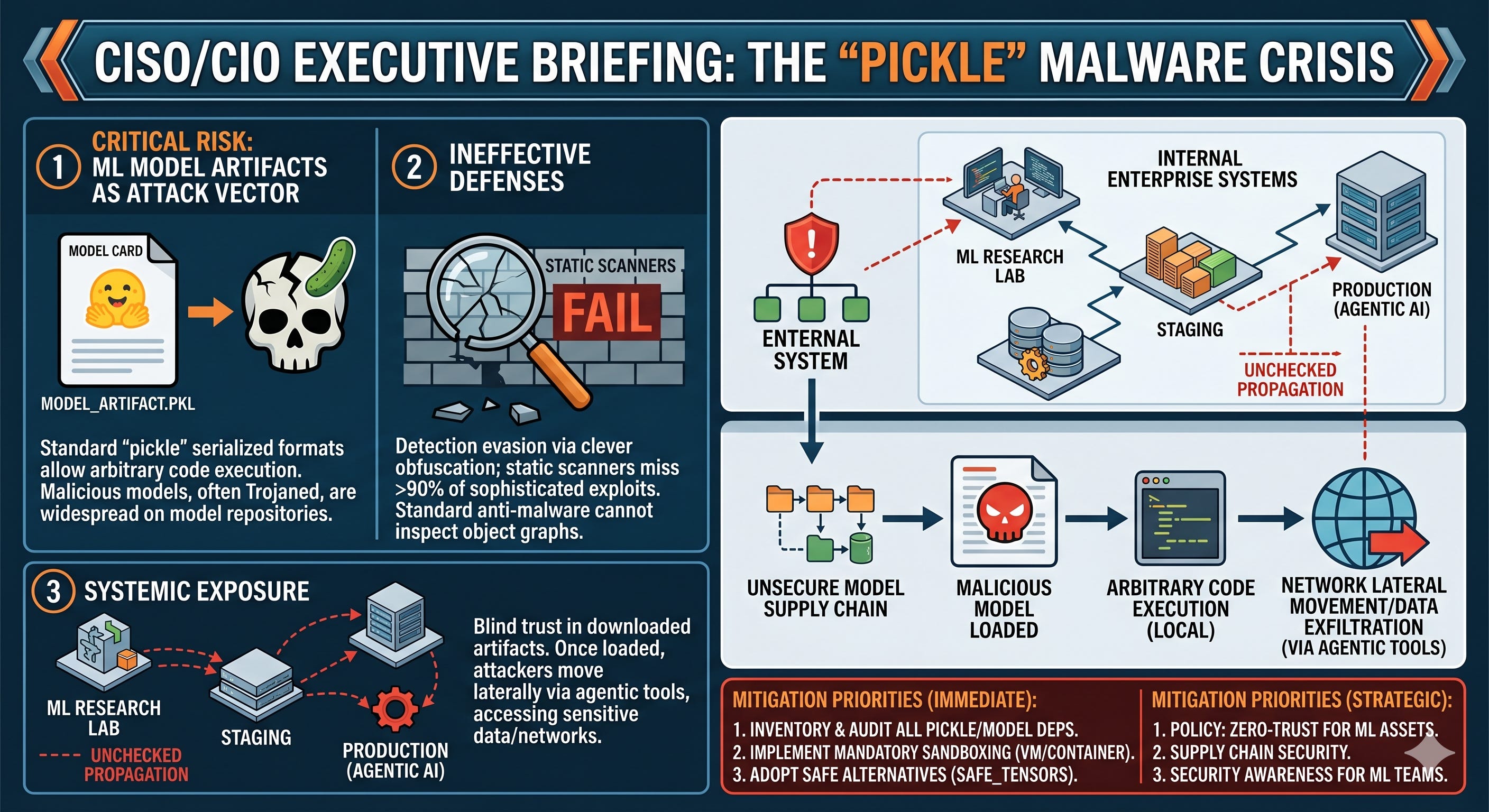
The integration of artificial intelligence and autonomous agentic workflows within corporate infrastructures has disrupted the foundational principles of information security. For the Chief Information Security Officer (CISO), Chief Information Officer (CIO), and senior systems engineer, this evolution invalidates traditional assumptions regarding threat detection, system trust, and code verification. This report provides a comprehensive, multi-layered strategic and technical framework designed to address these challenges, shifting enterprise security from legacy static code analysis to real-time, hardware-enforced runtime containment.
Stochastic vs. Formal Systems: The Foundational AI Security Divide
A primary vulnerability in contemporary enterprise AI strategies is the reliance on traditional security frameworks to assess machine learning models.1 This approach fails because it overlooks a fundamental division in computer science: the operational divergence between formal software systems and stochastic, non-formal neural systems.1
The Limits of Static Code Analysis
Traditional software architectures represent formal systems.1 These systems are compiled or interpreted using deterministic, symbolic logic where programmatic instructions map directly to predictable execution pathways and semantic outcomes.1 Because formal systems rely on deterministic execution, static analysis tools (such as SAST and dependency scanners) can programmatically parse and reason about the code structure, identifying known vulnerabilities, unauthorized logical pathways, or malicious signatures before runtime.1
In contrast, deep neural networks represent stochastic, probabilistic systems.1 At its core, deep learning inference is a sequence of non-linear mathematical operations executed over multi-dimensional tensor arrays, formulated as:
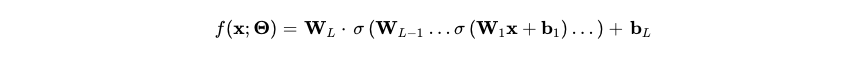
Within this framework,
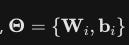
this represents billions of floating-point weights and biases optimized during training. Because these architectures lack explicit symbolic logic and defined semantics, the system does not execute structured instructions; rather, it approximates numerical probabilities.1
Consequently, there is no viable security mechanism capable of parsing a raw model file to determine if it will execute malicious actions during inference.1 Securing a neural network through static structural analysis is a fundamental mathematical limitation.1 This necessitates a transition to runtime isolation and behavioral containment.

Supply-Chain Realities: Serialized Code Exploits and the Inadequacy of Existing Scanners
The open-source AI supply chain remains heavily exposed to systemic exploitation.4 Because organizations frequently import pre-trained models from public repositories like Hugging Face, they introduce unique software supply chain risks that bypass standard endpoint detection and response (EDR) agents.4
Malicious Serialization and Remote Code Execution
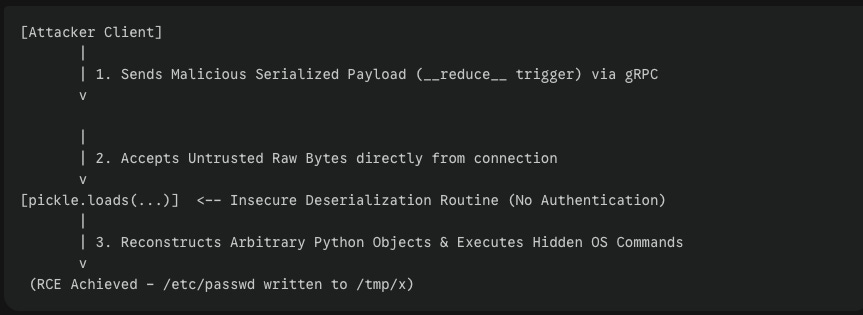
The prevalence of legacy model serialization formats, primarily Python’s pickle module, represents an immediate threat vector.4 Designed as a stack-based serialization protocol, pickle reconstructs arbitrary Python objects during file loading.6 Attackers leverage this behavior by embedding malicious system commands directly into model weight files using pythonic constructors like __reduce__().7
A critical real-world example of this vulnerability is CVE-2026-25874, identified in the Hugging Face LeRobot asynchronous inference PolicyServer.7 The service accepted raw bytes over unauthenticated gRPC endpoints, routing them directly to pickle.loads(...).7 Attackers leveraged this endpoint to achieve unauthenticated remote code execution (RCE) at the system privilege level of the calling process, demonstrating how easily a serialized model format can serve as a direct command execution vector.7
This issue is widespread in the AI ecosystem.4 Research shows that 44.9% of popular models hosted on Hugging Face continue to rely on the insecure pickle format.4 Furthermore, 15% of these repositories contain models that cannot be loaded by secure alternatives, such as PyTorch’s weights-only unpickler, creating a significant dependency on insecure deserialization paths.4
While alternative formats like Safetensors restrict model files strictly to numeric tensor arrays and JSON metadata, the transition is slow.4 Even automated conversion pipelines are targeted.5 For instance, vulnerabilities in Hugging Face’s automated conversion spaces allowed attackers to upload compromised models that hijacked the associated converter service bot.5 This enabled adversaries to issue unauthorized pull requests and inject malicious code across arbitrary public repositories under the guise of the official platform bot.5
Bypassing Static Model Analyzers
To protect developers, model registries use static analysis tools like picklescan alongside standard malware engines.6 However, these security controls can be bypassed through archive manipulation and structure evasion.8

Furthermore, researchers regularly identify malicious models on public hubs that contain embedded backdoors executing reverse shells, collecting system fingerprints, and harvesting SSH credentials.4 This is not isolated to PyTorch; TensorFlow Keras models are also vulnerable to arbitrary code execution through embedded Lambda layers, which can execute system-level operations when the model architecture is parsed.6
The Enterprise Risk Profile: Shadow AI and Insider Threat Amplification
For CISOs and CIOs, securing the machine learning pipeline is only one aspect of a broader challenge.9 The rapid, uncoordinated adoption of external Generative AI tools by employees (known as Shadow AI) creates a significant unmonitored attack surface.9
The Financial and Regulatory Realities of Shadow AI
Shadow AI bypasses standard security monitoring, introducing significant data governance risks 9:
Widespread Exposure: Surveys indicate that up to 77% of employees admit to copying and pasting sensitive corporate data into unapproved public AI systems.9 Similarly, localized studies show that 43% of workers frequently input proprietary business logic, system credentials, or database schemas into public chatbots to refactor or analyze code.11
High-Value Data Leakage: According to IBM’s security research, approximately 20% of all recorded enterprise breaches are linked to Shadow AI.9 When these breaches occur, they are highly costly, increasing remediation expenses by an average of $670,000.9 These incidents are also qualitatively damaging, exposing personally identifiable information (PII) 65% of the time and intellectual property 40% of the time.9
Infrastructure Blind Spots: The average large enterprise unknowingly hosts over 1,200 unofficial AI applications.9 This footprint is further complicated by an average of 15,000 “ghost users”—dormant credentials that can be exploited by unauthorized automated integrations.9 When credentials or passwords are shared with AI assistants, the average time to detect and remediate the exposure is 94 days, leaving a long window of vulnerability.9
Generative AI as a Cognitive Insider Amplifier
In addition to accidental data exposure, Generative AI introduces new insider threat dynamics.12 Generative models can act as a “cognitive amplifier” for malicious or negligent insiders.12
Traditional insider threats are constrained by the adversary’s technical expertise.12 However, conversational AI systems provide real-time guidance, validation, and optimization of attack steps.12 Because these models are designed to engage and assist, they can inadvertently validate a user’s reasoning, provide optimized payloads, and recommend execution paths.12 This lowers the barrier to entry, enabling non-technical insiders to plan and execute sophisticated security incidents.12
Traditional Insider Threat:
[Insider Motivation] ---> --->
AI-Amplified Insider Threat:
[Insider Motivation] ---> [Conversational AI Hype Machine (Validates/Optimizes)] ---> --->
Hardening the Local Model Runtime: A Seven-Layer Sandboxing Architecture
When senior systems engineers deploy local LLM runtimes (such as llama-server) or integrate autonomous agents (such as OpenClaw), they must treat the model as untrusted code.2
The Fallacy of Prompt-Based Guardrails
A common architectural flaw in agentic AI implementations is relying on system prompts or instructional guidelines to enforce security boundaries.13 This approach often fails.13 When LLM agents are granted tool-calling access—such as the ability to execute system commands, write files, or query internal databases—they are vulnerable to prompt injection and runtime hallucination.3
For example, OpenClaw recently resolved a critical sandbox escape (version 2026.3.28) where a compromised prompt allowed a message tool to read arbitrary host files outside the designated directory.13 Relying on natural language prompts to secure an execution boundary is ineffective; system permissions and sandbox containment must be enforced programmatically outside the model runtime.13
Implementing the Seven-Layer Isolation Framework
To safely run local machine learning models and autonomous tools, systems engineers can implement a hardware-virtualized sandbox based on a multi-layered defense-in-depth model.3 This architecture isolates the runtime environment inside a virtual guest operating system, restricting access to network, process, and file system resources.3
+-------------------------------------------------------------------------------------------------+
| PHYSICAL GUEST VM LAYER (UTM/Apple) |
| |
| +-----------------------------------------------------------------------------------------+ |
| | Layer 3: VM Internal pf Firewall (Local Kernel Filtering) | |
| +-----------------------------------------------------------------------------------------+ |
| | |
| v |
| +-----------------------------------------------------------------------------------------+ |
| | Layer 4: System Proxy Environment Vars (/etc/profile.d) | |
| +-----------------------------------------------------------------------------------------+ |
| | |
| v |
| +-----------------------------------------------------------------------------------------+ |
| | Layer 5: Non-Privileged Standard User Space (openclaw) | |
| +-----------------------------------------------------------------------------------------+ |
| | |
| v |
| +-----------------------------------------------------------------------------------------+ |
| | Layer 6: Per-Process Network Enforcement (LuLu/Auditd) | |
| +-----------------------------------------------------------------------------------------+ |
| | |
| v |
| +-----------------------------------------------------------------------------------------+ |
| | Layer 7: Human-in-the-Loop Intercept (Circuit Breaker) | |
| +-----------------------------------------------------------------------------------------+ |
| | |
| v |
| [Agent Execution Engine] |
+-------------------------------------------------------------------------------------------------+
The seven runtime containment layers are structured as follows:
Layer 1: Host-Level Packet Filter (pf) Firewall
The host physical hypervisor separates the host network (192.168.2.x) from the private guest VM network (192.168.64.x).3 The host packet filter (pf) rules restrict VM traffic strictly, allowing outbound access only to:
The local DNS server (192.168.2.1) via UDP Port 53.3
Designated local storage arrays (NAS) over SMB via Ports 445 and 139.3
Authorized local LLM engines running on dedicated compute servers via Ports 4000, 8081, 8082, and 8083.3 Direct HTTP/HTTPS outbound traffic is blocked to prevent the guest VM from bypassing the local proxy.3
Layer 2: Domain-Whitelisting Forward Proxy
To permit necessary package downloads or API connectivity while maintaining control, all outbound internet traffic is routed through a local Squid proxy.3 The proxy enforces a strict, explicit domain whitelist (e.g., .pypi.org, .github.com, .huggingface.co).3 Any connection request to unapproved external endpoints is denied and logged for review.3
Layer 3: VM-Internal Firewall
To mitigate the risk of guest-level root privilege escalation, a secondary, local pf firewall is initiated inside the guest VM kernel.3 This configuration mirrors Layer 1’s blocking rules, ensuring that network restrictions remain active even if the hypervisor boundary is compromised.3
Layer 4: System-Wide Proxy Mapping
To prevent client applications or developer libraries from bypassing the Squid proxy, proxy variables are defined globally within the guest VM configuration (/etc/profile.d/proxy.sh) 3:
Bash
export http_proxy=”http://192.168.64.1:3128”
export https_proxy=”http://192.168.64.1:3128”
export no_proxy=”*.local,127.0.0.1,localhost,192.168.64.*”
Layer 5: Non-Privileged Standard User Execution
The AI agent or inference runtime executes under a dedicated, unprivileged standard user account (e.g., openclaw).3 This standard user is blocked from modifying firewall configurations, accessing system logs, or installing system package dependencies.3
Layer 6: Process-Level Network Auditing
An auditing utility (such as LuLu for macOS or auditd for Linux) is configured within the guest operating system.3 This layer monitors process activity, mapping network traffic to specific process IDs.3 If a standard system binary (such as curl or wget) attempts to initiate an outbound connection, the engine halts the execution and prompts the administrator for manual approval.3
Layer 7: Human-in-the-Loop Intercept
The outermost boundary uses a “human-in-the-loop” approval process for high-risk actions.2 Any commands involving external communication, file writes outside the sandboxed directory, or model alterations trigger an interactive confirmation dialog.2 This provides an administrative circuit breaker to prevent autonomous exploits.2
Alternative: Bubblewrap Sandboxing
As an alternative to full hypervisor virtualization, organizations can implement lightweight runtime sandboxing using bubblewrap.2 This approach relies on Linux namespaces to create isolated, read-only root filesystems, restricting the model runtime’s access to specified directories.2
This setup is combined with port-restricted local daemons.2 Rather than granting an agent direct access to network APIs or communication channels, services (like database interfaces or messaging clients) run as local daemons on restricted ports (e.g., Port 6000).2 The sandboxed model is granted access only to that specific local port under strict API schemas, protecting the broader operating system from lateral traversal.2
Strategic Governance: Balancing Innovation and Exposure
To address the risks of AI adoption while enabling business innovation, CISOs and CIOs must implement structured governance frameworks that avoid ineffective, heavy-handed restrictions.10
[AI Governance Model]
|
+----------------------+----------------------+
| |
v v
[Lightweight Intake & PMO]
- Multi-stakeholder reviews - Private API gateways
- Swift tool approvals - Locally hosted models
Transitioning from Restriction to Enabled Containment
Avoid Blanket Bans: Absolute bans on Generative AI tools are rarely effective.10 Such restrictions often drive usage underground, forcing employees onto personal devices or unmonitored browser sessions.10 This reduces visibility and increases the risk of undetected data leakage.10
Establish Lightweight Approval Pipelines: Implement a structured, multi-stakeholder intake process managed by the PMO.10 This pipeline should include fast, concurrent reviews by legal, privacy, and security teams.14 The objective is to evaluate a tool’s data retention policies, model serialization safety, and host network exposure quickly, granting or denying access within days to minimize friction.10
Offer Sanctioned Enterprise Alternatives: The most effective way to eliminate Shadow AI is to provide employees with safe, authorized alternatives.10 Organizations should deploy private API gateways or internally hosted model frontends.10 These environments must be backed by enterprise service level agreements (SLAs) ensuring that inputs are never used for model training, mitigating data leakage concerns.9
Enforce Role-Based AI Usage Policies: Access permissions should align with job functions and data requirements.10 For example, design teams may use sanctioned image generation tools, while developers are permitted to use local LLM instances inside secure network segments.10 However, the use of production database schemas or customer PII as model inputs remains strictly prohibited across all roles.10
This approach allows organizations to leverage AI capabilities while maintaining strong, programmatic security controls across the enterprise.10
In Summary:
As a CISO, CIO and cyber leader , you must recognize that traditional cybersecurity frameworks are fundamentally blind to the unique threat vectors of enterprise AI: because deep neural networks are stochastic, probabilistic systems rather than deterministic, symbolic code, static security scanners cannot programmatically predict or verify if a model contains malicious execution pathways. Threat actors are actively exploiting this architectural blind spot, using legacy serialization formats like Python's ‘pickle’ to easily bypass static checkers, execute unauthenticated remote code (RCE) at the system privilege level, and establish persistent backdoors. Compounding this supply-chain risk is the massive, unmonitored growth of Shadow AI—which silently leaks proprietary intellectual property, increases average breach remediation costs by $670,000, and acts as a "cognitive amplifier" that allows non-technical insiders to plan and execute sophisticated cyberattacks.
To protect your organization, you must act now: abandon ineffective blanket bans that only drive risky AI usage underground, and immediately deploy a dual-pronged defense of providing sanctioned, enterprise-grade AI gateways alongside a programmatic, multi-layered runtime isolation architecture—enforcing strict VM sandboxing, global domain proxy whitelisting, and mandatory human-in-the-loop firewalls to contain all local models as untrusted, high-risk code.
Works cited
My self-sovereign / local / private / secure LLM setup, April 2026, accessed May 19, 2026, https://vitalik.eth.limo/general/2026/04/02/secure_llms.html
How to Run Agentic AI Safely: A Complete Sandbox Isolation Guide ..., accessed May 19, 2026, https://manjit28.medium.com/sandboxing-agentic-ai-a-practical-security-guide-for-openclaw-and-agentic-ai-in-general-a794640d876e
PickleBall: Secure Deserialization of Pickle-based Machine Learning Models - arXiv, accessed May 19, 2026, https://arxiv.org/html/2508.15987v1
Silent Sabotage: Hijacking Safetensors Conversion on Hugging Face - HiddenLayer, accessed May 19, 2026, https://www.hiddenlayer.com/research/silent-sabotage
Data Scientists Targeted by Malicious Hugging Face ML Models with Silent Backdoor, accessed May 19, 2026, https://jfrog.com/blog/data-scientists-targeted-by-malicious-hugging-face-ml-models-with-silent-backdoor/
CVE-2026-25874: Hugging Face LeRobot Unauthenticated RCE via Pickle Deserialization, accessed May 19, 2026, https://www.resecurity.com/blog/article/cve-2026-25874-hugging-face-lerobot-unauthenticated-rce-via-pickle-deserialization
Exposing 4 Critical Vulnerabilities in Python Picklescan - Sonatype, accessed May 19, 2026, https://www.sonatype.com/blog/bypassing-picklescan-sonatype-discovers-four-vulnerabilities
What Is Shadow AI? Definition | Proofpoint US, accessed May 19, 2026, https://www.proofpoint.com/us/threat-reference/shadow-ai
What Is Shadow AI? How It Happens and What to Do About It - Palo Alto Networks, accessed May 19, 2026, https://www.paloaltonetworks.com/cyberpedia/what-is-shadow-ai
6 Biggest Shadow AI Risks and How to Mitigate Them - Knostic, accessed May 19, 2026, https://www.knostic.ai/blog/shadow-ai-risks
AI Insider Threats: How Generative AI is Changing Insider Risk - Darktrace, accessed May 19, 2026, https://www.darktrace.com/blog/ai-insider-threats-how-generative-ai-is-changing-insider-risk
Why you need to be careful giving your local LLMs tool access: OpenClaw just patched a Critical sandbox escape : r/LocalLLaMA - Reddit, accessed May 19, 2026, https://www.reddit.com/r/LocalLLaMA/comments/1s8md7v/developing_situation_why_you_need_to_be_careful/
The CISO’s guide to responding to shadow AI - CSO Online, accessed May 19, 2026, https://www.csoonline.com/article/4143302/the-cisos-guide-to-responding-to-shadow-ai.html